




Article publié le 16 avril 2026 – informations vérifiées sur les annonces officielles d’Anthropic.
Ce qu’Anthropic annonce officiellement
Anthropic a rendu disponible Claude Opus 4.7 le 16 avril 2026, accessible immédiatement sur Claude.ai, l’API Anthropic, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry (source officielle Anthropic).
Le modèle remplace Claude Opus 4.6 sorti deux mois plus tôt, et se positionne comme « le modèle le plus capable généralement disponible » d’Anthropic – la nuance est volontaire, parce qu’un modèle plus puissant existe en interne. On y revient.
- ID API :
claude-opus-4-7 - Entrée : 5 $ par million de tokens
- Sortie : 25 $ par million de tokens
- Identique à Opus 4.6 (mais voir plus bas, c’est plus subtil que ça en a l’air)
Les nouveautés concrètes de Claude Opus 4.7
Vision haute résolution : 3,75 mégapixels
C’est la première fois qu’un modèle Claude grimpe à cette résolution. Avant, on plafonnait à 1 568 px sur le grand côté (1,15 MP). Désormais, 2 576 px (3,75 MP) – soit environ 3 × la capacité visuelle des modèles précédents (documentation Anthropic).
Ça change quoi en vrai ? Les workflows lourds en images (analyse de captures d’écran, lecture de documents scannés, computer use) deviennent franchement utilisables. Et bonus pratique : les coordonnées du modèle sont maintenant 1:1 avec les pixels réels – fini les calculs de facteur d’échelle.
À noter : les images en haute résolution consomment plus de tokens. Si la précision visuelle n’est pas critique, downsamplez avant d’envoyer.
1 million de tokens de contexte au tarif standard
Personne n’en parle assez. Claude Opus 4.7 supporte 1M de tokens de contexte sans premium long-contexte. Comparé à GPT-5 ou Gemini, ça veut dire que vous pouvez envoyer un codebase entier, un livre complet ou plusieurs PDFs sans que le compteur s’affole.
Sortie maximale : 128k tokens.
Adaptive thinking (et seulement ça)
Anthropic a tué l’ancien système de thinking budget (où tu spécifiais budget_tokens: 32000). Désormais, adaptive thinking est le seul mode de raisonnement actif, et le modèle alloue lui-même son budget selon la complexité.
Pour les développeurs : si vous mettiez thinking: {"type": "enabled", "budget_tokens": N}, ça renvoie maintenant une erreur 400. Faut migrer vers :
thinking = {"type": "adaptive"}
output_config = {"effort": "high"}⚠️ Adaptive thinking est OFF par défaut sur Opus 4.7. Vous devez l’activer explicitement.
Task budgets (bêta) – la fonctionnalité qui change tout
Vous donnez à Claude un budget approximatif de tokens pour une boucle agentique entière (réflexion + appels d’outils + sorties). Le modèle voit un compte à rebours et ajuste sa stratégie pour finir proprement avant la limite.
Concrètement : pour des agents qui peuvent dérailler en utilisation réelle (looper, surfocaliser, s’éparpiller), c’est le filet de sécurité qui manquait.
Activation via le header task-budgets-2026-03-13. Budget minimum : 20k tokens.
Le nouveau niveau d’effort xhigh
Entre high et max, Anthropic introduit un cran intermédiaire : xhigh. Recommandé par défaut pour le code et l’agentique. C’est le sweet spot intelligence/coût pour la plupart des cas d’usage exigeants.
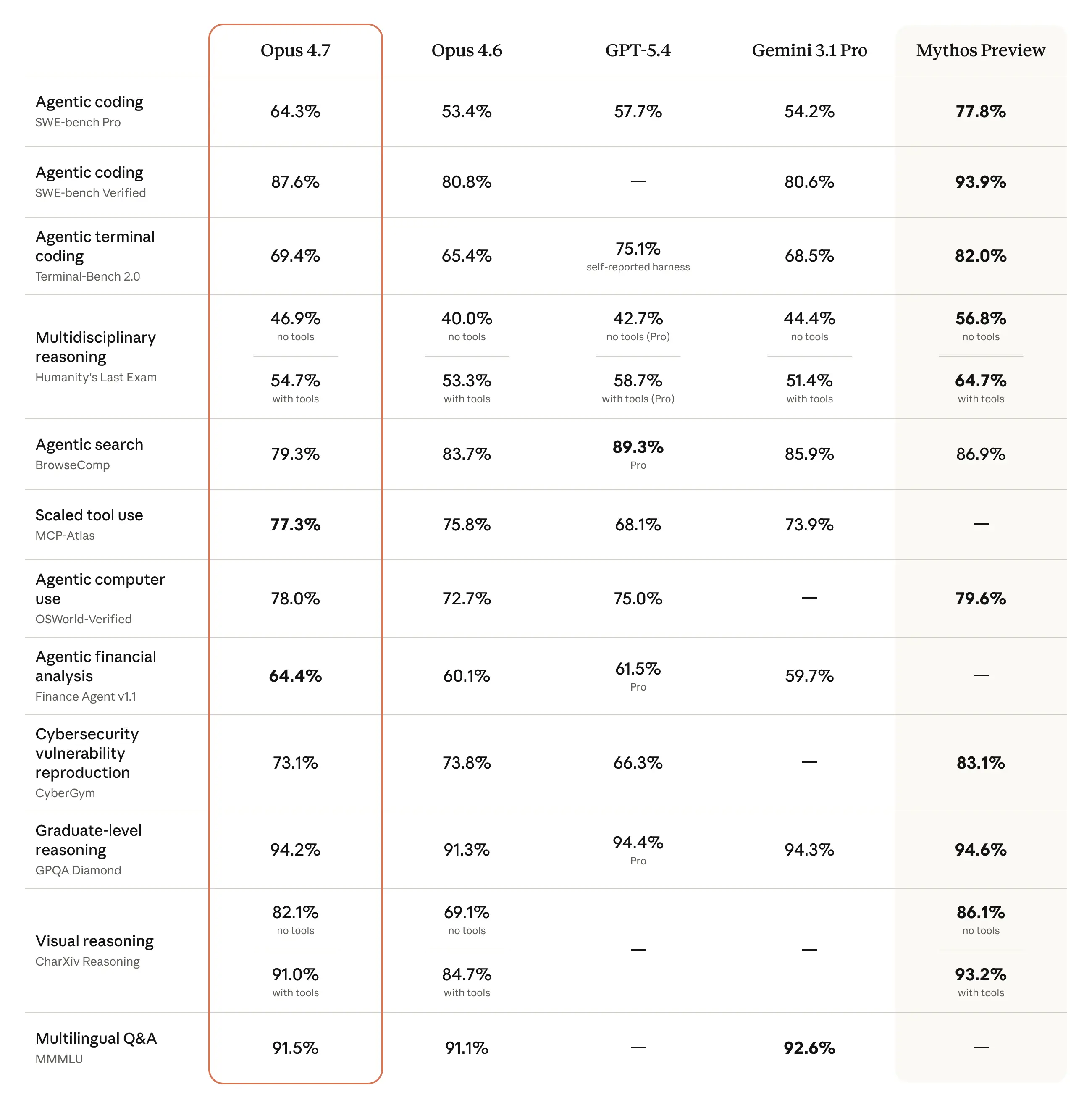
Les chiffres : benchmarks de Claude Opus 4.7 vs 4.6
Les vrais chiffres communiqués par Anthropic :
| Benchmark | Opus 4.6 | Opus 4.7 | Delta |
|---|---|---|---|
| SWE-Bench Verified | baseline | +13 % | 4 tâches résolues en plus |
| CursorBench | 58 % | 70 % | +12 pts |
| OfficeQA Pro | baseline | -21 % d’erreurs | nette amélioration |
| Vision XBOW | 54,5 % | 98,5 % | +44 pts (énorme) |
| Finance Agent (général) | 0,767 | 0,813 | +6 % |
| BigLaw Bench | – | 90,9 % | effort élevé |
| Rakuten-SWE-Bench | baseline | 3 × plus de tâches résolues | majeur |
Le bond sur la vision (98,5 % vs 54,5 %) est le chiffre le plus impressionnant. Il valide directement la nouvelle résolution image.
Citation parlante : « Low-effort Opus 4.7 équivaut à medium-effort Opus 4.6 » – CTO de Hex, cité dans l’annonce officielle. Autrement dit, vous payez moins cher pour la même qualité, si vous configurez bien.
Le tokenizer change : ce que ça implique pour vos coûts
C’est le point qu’aucun article généraliste ne mentionne, et c’est pourtant le plus important côté budget.
Anthropic a déployé un nouveau tokenizer sur Claude Opus 4.7. Le même contenu – un paragraphe en anglais, une fonction Python, un payload JSON – peut désormais être découpé en 1,0× à 1,35× plus de tokens que sur Opus 4.6 (documentation officielle).
Le multiplicateur est plus élevé sur :
- Le code (Python, JS, etc.)
- Les données structurées (JSON, XML)
- Les langues non-anglaises (donc le français)
Conséquence pratique : le tarif affiché « identique à 4.6 » est techniquement vrai, mais votre facture mensuelle peut grimper de 20-35 % à usage équivalent. Pas un drame, mais à savoir.
Outils à utiliser pour limiter la casse : task_budget, effort ajusté, et les nouveaux prompt caching (jusqu’à 90 % d’économies) et batch processing (50 % d’économies).
Mythos : le grand absent (volontaire) du lancement
Le storytelling le plus intéressant de cette sortie, c’est ce qu’Anthropic n’a pas sorti.
Mythos est un modèle déjà entraîné, plus capable que Claude Opus 4.7. Anthropic le confirme noir sur blanc dans son annonce : Opus 4.7 « trails Mythos » – il est volontairement bridé en cybersécurité pour servir de terrain de test aux nouveaux garde-fous avant un déploiement plus large des modèles type Mythos (CNBC, Axios).
Concrètement, Claude Opus 4.7 embarque :
- Détection et blocage automatiques des requêtes liées à des usages cybersécurité interdits ou à risque
- Un Cyber Verification Program : les chercheurs en sécurité légitime (red team, pentest, recherche de vulnérabilités) peuvent demander un accès élargi via ce formulaire
Mon interprétation : Anthropic prépare le terrain pour Mythos en collectant un an de données sur ces garde-fous en production. C’est une stratégie inverse d’OpenAI, qui sort ses modèles les plus capables direct au public.
Breaking changes pour les développeurs
Si vous utilisez l’API Messages d’Anthropic, trois choses cassent en passant à Claude Opus 4.7. Pas négligeable.
1. temperature, top_p, top_k ne sont plus acceptés
Toute valeur non-défaut renvoie une erreur 400. Migration recommandée : enlever ces paramètres de vos requêtes et guider le modèle par le prompt.
2. Extended thinking budgets supprimés
# Avant (Opus 4.6)
thinking = {"type": "enabled", "budget_tokens": 32000}
# Après (Opus 4.7)
thinking = {"type": "adaptive"}
output_config = {"effort": "high"}3. Le contenu des thinking blocks est masqué par défaut
Si votre produit affichait le raisonnement de Claude en streaming, l’utilisateur verra maintenant une longue pause avant la sortie. Pour restaurer la visibilité :
thinking = {
"type": "adaptive",
"display": "summarized", # ou "omitted" (defaut)
}À noter : pas de breaking changes si vous utilisez Claude Managed Agents.
Les changements de comportement à connaître
Pas des erreurs, mais ça peut casser vos prompts :
- Suivi des instructions plus littéral : le modèle ne généralise plus implicitement. Si vous demandez « formate en bold », il ne formatera pas en italique « pour faire varier ».
- Longueur des réponses calibrée à la complexité perçue (plus de verbosité fixe par défaut)
- Moins d’appels d’outils par défaut, plus de raisonnement
- Ton plus direct, moins de validation (« Excellente question ! ») et moins d’emojis que la 4.6
- Mises à jour de progression plus régulières dans les longues traces agentiques
- Moins de subagents lancés par défaut
Si vous avez ajouté du scaffolding pour forcer ces comportements (« vérifie deux fois », « envoie un message intermédiaire »), enlevez-les et re-baselinez.
Comment accéder à Claude Opus 4.7
Cinq points d’entrée pour utiliser le modèle aujourd’hui :
| Plateforme | Pour qui | Accès |
|---|---|---|
| Claude.ai | Grand public | Inclus dans Pro, Max, Team, Enterprise |
| API Anthropic | Développeurs | claude-opus-4-7 |
| Amazon Bedrock | Entreprises AWS | Disponible immédiatement (annonce AWS) |
| Google Cloud Vertex AI | Entreprises GCP | Disponible |
| Microsoft Foundry | Entreprises Azure | Disponible |
Pour tester rapidement sans budget : ouvrez un compte Claude.ai gratuit, mais sachez que Claude Opus 4.7 est gated derrière un plan payant. Pour comparer plusieurs IA dans une même interface, j’avais déjà testé Mammouth AI qui agrège GPT, Claude et Gemini.
Mon avis sur Claude Opus 4.7
Je vais être direct : ce n’est pas la sortie qui change le monde. Et c’est pas un problème.
Ce qui me plait vraiment :
- Le 1M de contexte sans surcoût, c’est concrètement utile dès demain matin
- Les task budgets vont sauver des milliers de bills d’API qui dérapaient
- La transparence sur Mythos : Anthropic admet publiquement qu’il garde le meilleur sous le coude. C’est inhabituel et ça construit de la confiance
- Le bond en vision (98,5 % sur XBOW) ouvre des cas d’usage screenshot/document qui étaient borderline avant
Ce qui me chiffonne :
- Le tokenizer +35 % rend la baseline de coût trompeuse. Anthropic aurait pu être plus clair là-dessus.
- Les breaking changes API vont casser pas mal d’intégrations existantes. Migration obligatoire.
- Le naming Opus 4.6 → 4.7 sous-vend le saut réel (sur la vision et l’agentique).
Si vous étiez déjà sur Opus 4.6 pour du code ou de l’agentique sérieux, migrez. Si vous utilisez Claude pour rédiger des emails, rien ne presse.
Pour des cas d’usage agentiques au quotidien, j’avais déjà parlé de Claude Cowork, qui devrait bénéficier directement de cette mise à jour.
FAQ – Claude Opus 4.7
Quand Claude Opus 4.7 a-t-il été lancé ?
Claude Opus 4.7 a été lancé officiellement le 16 avril 2026 par Anthropic, disponible immédiatement sur Claude.ai, l’API Anthropic, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry.
Combien coûte Claude Opus 4.7 ?
Le tarif officiel est de 5 $ par million de tokens en entrée et 25 $ par million de tokens en sortie, identique à Claude Opus 4.6. Attention toutefois : le nouveau tokenizer génère 1,0 à 1,35 fois plus de tokens, ce qui peut faire grimper la facture réelle de 20-35 %.
Claude Opus 4.7 est-il plus puissant que GPT-5 ou Gemini 3 ?
Anthropic le positionne comme leader sur l’ingénierie logicielle agentique, avec 70 % sur CursorBench (vs 58 % pour Opus 4.6) et 98,5 % sur le benchmark vision XBOW. La comparaison directe avec GPT-5 et Gemini 3 dépend du cas d’usage : Claude excelle en code et tâches longues, GPT garde l’avantage en multimodal général, Gemini est imbattable sur le contexte ultra-long natif.
Qu’est-ce que Mythos et pourquoi n’est-il pas public ?
Mythos est un modèle d’Anthropic plus puissant que Claude Opus 4.7, déjà entraîné mais réservé à des partenaires sélectionnés. Anthropic l’a volontairement gardé en accès restreint pour tester d’abord les nouveaux garde-fous cybersécurité sur Claude Opus 4.7. L’objectif : déployer plus largement les modèles de classe Mythos quand les protections seront éprouvées.
Quelle est la fenêtre de contexte de Claude Opus 4.7 ?
Claude Opus 4.7 supporte une fenêtre de contexte de 1 million de tokens au tarif standard, sans premium long-contexte. La sortie maximale est de 128 000 tokens.
Quelle est la résolution maximale d’image supportée ?
Claude Opus 4.7 accepte des images jusqu’à 2 576 pixels sur le grand côté, soit environ 3,75 mégapixels. C’est trois fois la résolution maximale des versions précédentes (1 568 px / 1,15 MP).
Y a-t-il des breaking changes pour les développeurs ?
Oui, trois changements cassants sur l’API Messages : les paramètres temperature, top_p et top_k ne sont plus acceptés (renvoient une erreur 400) ; les extended thinking budgets sont supprimés au profit d’adaptive thinking ; le contenu des thinking blocks est masqué par défaut. Aucun breaking change pour les utilisateurs de Claude Managed Agents.
Que sont les task budgets dans Claude Opus 4.7 ?
Les task budgets (en bêta) permettent de donner à Claude un budget approximatif de tokens pour une boucle agentique complète. Le modèle voit un compte à rebours et ajuste sa stratégie pour finir proprement. Budget minimum : 20 000 tokens. Activation via le header beta task-budgets-2026-03-13.
Faut-il migrer immédiatement de Claude Opus 4.6 vers 4.7 ?
Pour des cas d’usage code, agents et vision : oui, le gain de performance le justifie largement. Pour de la rédaction simple ou du chatbot conversationnel : rien ne presse, Opus 4.6 reste largement suffisant et les breaking changes API exigent une migration testée. Anthropic propose un guide de migration officiel pas-à-pas.
Claude Opus 4.7 est-il accessible au Canada ?
Oui, Claude Opus 4.7 est disponible au Canada sans restriction géographique, via Claude.ai (plans Pro, Max, Team, Enterprise) ou via les fournisseurs cloud Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry.
Conclusion
Claude Opus 4.7 n’est pas la révolution annoncée par les titres putaclic, mais c’est une mise à jour solide et stratégique. Le 1M de contexte standard, l’adaptive thinking et les task budgets sont des armes concrètes pour quiconque construit du sérieux avec Claude. Le bond en vision est réel et change la donne sur les workflows screenshot/document.
Le vrai signal, c’est ce qu’Anthropic prépare derrière : Mythos. En sortant Claude Opus 4.7 comme banc d’essai pour ses garde-fous, l’entreprise admet ouvertement qu’elle freine volontairement la course à la puissance – pour la sécuriser. C’est rare, c’est sain, et ça contraste fort avec le rythme d’OpenAI ou xAI.
Reste à voir si cette stratégie tiendra face à la pression concurrentielle. Mais pour aujourd’hui, Claude Opus 4.7 est sans doute le modèle le plus pragmatique pour de la production.



